将低维数据映射到高维数据对分类可能是有益的,例如:
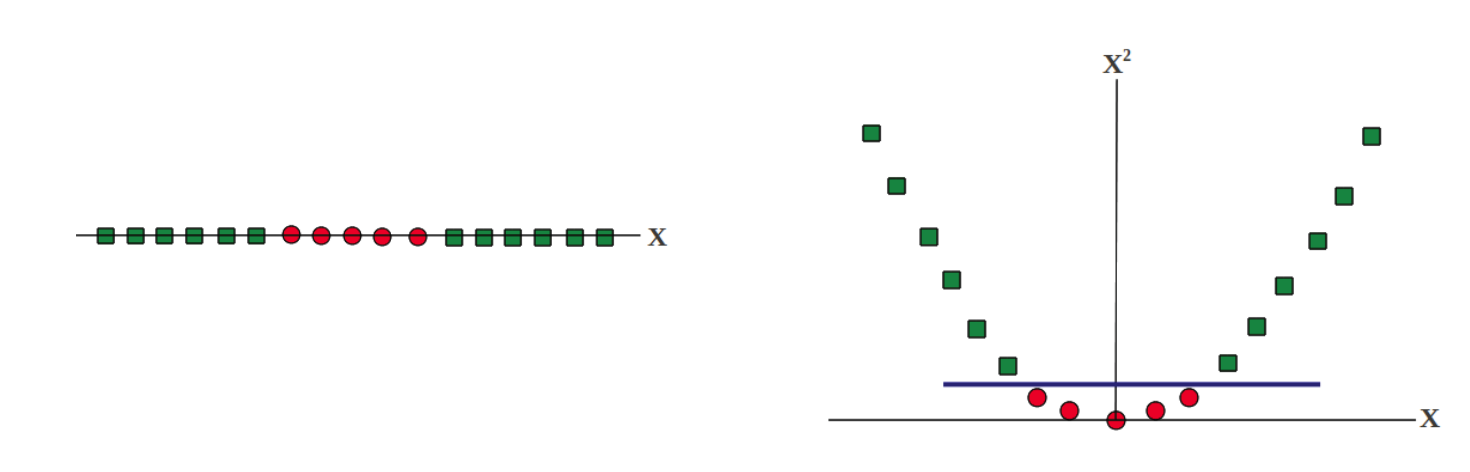
原SVM的优化问题为:
\[\textrm{min }\frac{1}{2}|w|^2 + C\sum{\xi_i}\] \[ \textrm{ s.t. } y_i(w^T x_i + b) \geq 1 - \xi_i, \xi_i \geq 0, \forall i\]
设\(\psi(x)\)将\(x\)映射为另一个向量,特征映射之后的决策函数变为\(h’(x) = \hat{w} \psi(x) + \hat{b}\),则优化问题变为:
\[\textrm{min }\frac{1}{2}|\hat{w}|^2 + C\sum{\xi_i}\] \[ \textrm{ s.t. } y_i(\hat{w}^T \psi(x_i) + \hat{b}) \geq 1 - \xi_i, \xi_i \geq 0, \forall i\]
对偶问题变为:
\[\textrm{min } Q(\alpha)=\frac{1}{2}\sum\sum{\alpha_i \alpha_j y_i y_j \psi(x_i)^T \psi(x_j)} - \sum{\alpha_i} \] \[\textrm{ s.t. } \sum{\alpha_i y_i}=0, C \geq \alpha_i \geq 0, \forall i\]
定义核函数:\(\kappa(x_i, x_j) = \psi(x_i)^T \psi(x_j)\)
定义正定核函数:对于\(K_{ij} = \kappa(x_i, x_j)\), 若\(K_{ij} = K_{ji}\)且\(K\)是半正定的(\(\forall \theta, \theta^T K \theta \geq 0\)),则称\(\kappa\)是正定核函数。
Mercer’s Condition: 若\(\kappa\)是正定核函数,则一定能找到一个Hilbert空间\(H\)和特征映射函数\(\psi\),使得\(\kappa(x_i, x_j)=\langle \psi(x_i), \psi(x_j) \rangle_{H}\)
常用核函数:
- 多项式核,\(\kappa(x_i, x_j) = (1 + \langle x_i, x_j \rangle)^m, m \in \mathbb{N}\)
- 高斯核,\(\kappa(x_i, x_j) = \exp(-\frac{|x_i - x_j|^2}{2 \sigma^2})\)
- 核函数的线性组合,\(\kappa(x_i, x_j) = \sum_{p=1}^m {\gamma_p \kappa_p(x_i, x_j)}, \gamma_p \geq 0\)
此时的对偶问题记作:
\[\min_\alpha \frac{1}{2}(\alpha \odot y)^T K (\alpha \odot y) + \alpha^T e\] \[\textrm{s.t. } \alpha^T y = 0, \alpha \geq 0\]
其中,\(\alpha\)是拉格朗日乘子,\(y = [y_1, y_2, …, y_n]^T\),\(K_{ij} = \kappa(x_i, x_j)\),\(e=[1, 1, …, 1]^T\)